
728x90
728x90
🔉 빅데이터 분석을 편리하게 해주는 파이썬 라이브러리인 Pandas에 대해 공부해보자!
pandas - Python Data Analysis Library
pandas pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming language. Install pandas now!
pandas.pydata.org
데이터 복사
☑️ copy() 이용
일단 얕은 복사 예시
import pandas as pd
korean =['가','나','다']
english =['K','N','D']
df = pd.DataFrame({"한국어":korean, "영어": english})
dfoutput:

df2 =df # 데이터 복사(얕은 복사)
df2output:

df2.columns=["국어","외국어"] # df2의 컬럼명 변경
df # 복사본의 컬럼명만 바꿨는데 원본의 컬럼명이 바뀜output:

df가 아닌 복사본 df2의 컬럼명을 바꾸었는데도 df의 컬럼명이 바뀐 걸 확인할 수 있다. 이유는 df2 = df2 경우 원본과 데이터/index 등 모든 것을 공유하게 된다. 이럴 경우 원본 데이터프레임의 데이터가 손상될 수 있다. 원본 데이터의 손상을 방지하려고 하면 copy() 함수를 사용하면 된다.
다시 데이터프레임을 만들어주고
import pandas as pd
korean =['가','나','다']
english =['K','N','D']
df = pd.DataFrame({"한국어":korean, "영어": english})
dfoutput:
df2 =df.copy() # 깊은 복사
# copy()함수의 매개변수로 deep이 있다.
# deep 은 True or False 의 값을 가지며 기본값은 True이다.
# False 경우 앞서 한 df2 =df 와 같은 얕은 복사를 한다.
df2output:

df2.columns=["국어","외국어"] # df2의 컬럼명 변경
df # 원본 데이터output:
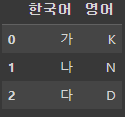
df2 # 복사본output:

copy()로 만들어진 복사본은 원본과는 완전하게 별개이다.
복사본의 컬럼명을 바꾸더라도 원본에는 영향을 미치지 않는다. 또 복사본을 바꾸더라도 원본에게 영향을 끼치지 않는다.
즉, 데이터의 원본을 보존하면서 데이터를 변환하려면 copy()를 사용하자
728x90
728x90
'Programming > Pandas' 카테고리의 다른 글
| [Pandas] 데이터 정렬(sort_values, sort_index) (0) | 2023.02.12 |
|---|---|
| [Pandas] 조건에 맞는 데이터 추출 (0) | 2023.02.12 |
| [Pandas] 원하는 위치의 데이터 추출(loc, iloc) (0) | 2023.02.12 |
| [Pandas] 시리즈(Series) 기초 (0) | 2023.02.05 |
| [Pandas] 데이터 프레임 생성, 컬럼명 추출&변경 (0) | 2023.02.03 |