
분류 모델 성능 평가지표로는 Confusion Matrix(오분류표)를 바탕으로 Accuracy, Precision, Recall, F1-Score 이 있다.
1. Confusion Matrix
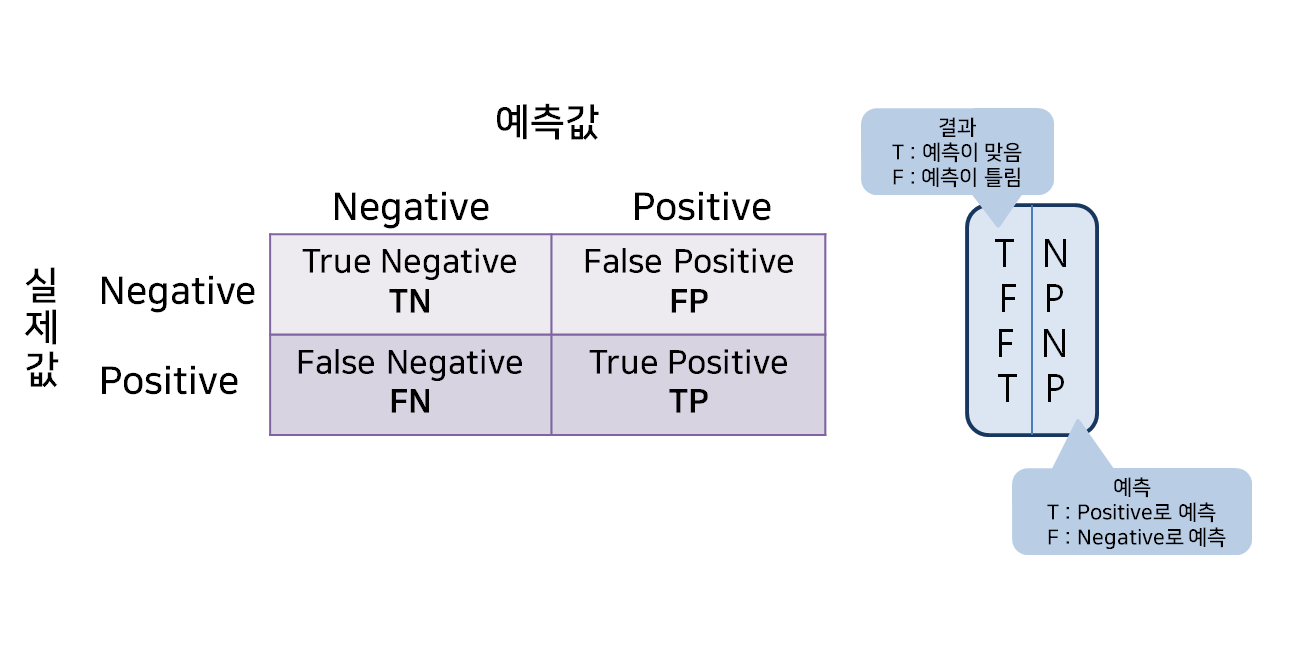
- TN : 음성으로 예측했는데 예측이 맞음! (음성으로 잘 예측한 것)
- TP : 양성으로 예측했는데 예측이 맞음! (양성으로 잘 예측한 것)
- FP : 양성으로 예측했는데 예측이 틀림! (예측 : 양성, 실제 : 음성)
- FN : 음성으로 예측했는데 예측이 틀림! (예측 : 음성, 실제 : 양성)
1.1 정확도 (Accuracy)
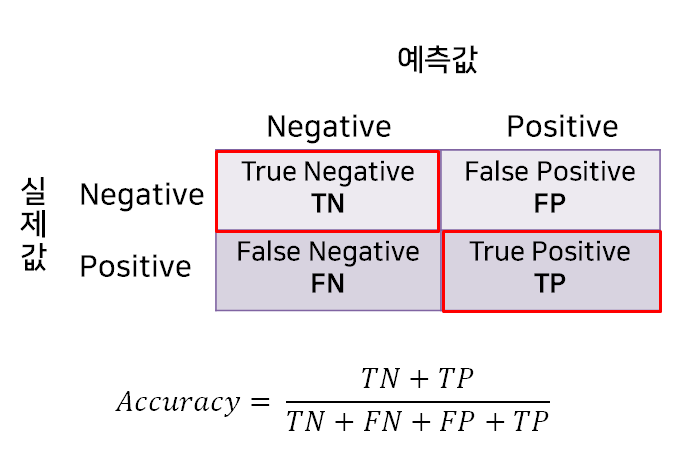
- 전체 중에서 양성, 음성 정확히 예측한(TN+TP) 비율
- 음성도 음성으로 예측한 경우도 옳은 예측임을 고려하는 평가지표
- 가장 직관적으로 모델 성능을 확인할 수 있는 평가지표
- 한계점으로 데이터 불균형시 제대로 분류했는지 알 수 없다.
1.2 정밀도 (Precision)
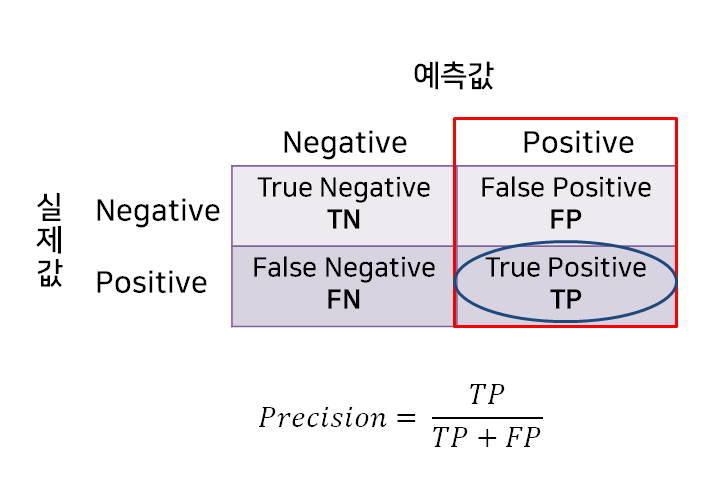
- 예측 관점에서 Positive라고 예측한 것 중에 실제 Positive인 비율
- ex) 비가 내릴 것으로 예측한 날 중에 실제 비가 내린 비율
- Positive 예측 성능을 정밀하게 측정하는 데 사용
1.3 재현율 (Recall)
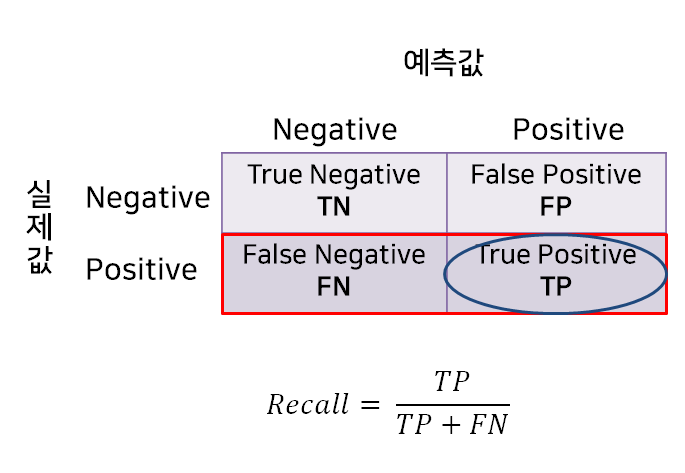
- 실제 관점에서 실제 Positive 중에서 Positive로 예측한 비율
- ex) 실제 비가 내릴 날 중에서 비가 내릴 것으로 예측한 날의 비율
- 실제 Positive를 얼마나 잘 예측했는지 나타내는 데 사용
1.4 정밀도와 재현율의 관계
정밀도와 재현율은 분자는 같고 분모만 다르기 때문에 Trade-off 관계를 가지고 있다.
정밀도가 더 중요한 경우
- 실제 음성인 데이터를 양성으로 잘못 판단하게 되는 경우 (정상 -> 비정상)
- ex) 스팸메일이 아닌데 스팸메일로 판단하는 경우
재현율이 더 중요한 경우
- 실제 양성인 데이터를 음성으로 잘못 판단하게 되는 경우 (비정상 -> 정상)
- ex) 암인데 암이라고 진단 내리지 않은 경우
재현율과 정밀도 모두 TP를 높이는 목적을 가지고 있지만, 재현율은 FN을 낮추는데 초점을 맞추고 있고 정밀도는 FP를 낮추는데 초점을 맞추고 있다.
모델의 성능을 평가할 때 둘 다 높은 수치를 얻는 것이 가장 좋고, 한 쪽은 높지만 다른 한 쪽은 매우 낮은 경우는 좋지 않은 모델이라고 평가할 수 있다.
2. F1-score
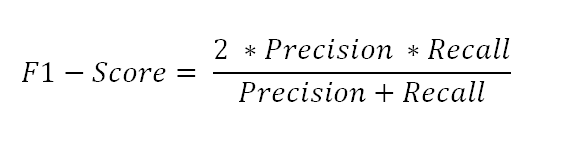
- Recall과 Precision의 조화평균
- Recall과 Precision 한 쪽으로 치우치지 않고 모두 클 때 큰 값을 가진다.
3. classification_report
위 방법을 한 번에 보여주는 코드이다. 오른쪽 맨 마지막은 개수이다.
# 모듈 불러오기
from sklearn.metrics import classification_report
# 성능 평가
print(classification_report(y_test,y_pred)) precision recall f1-score support
0 0.83 0.90 0.86 84
1 0.86 0.76 0.81 66
accuracy 0.84 150
macro avg 0.84 0.83 0.84 150
weighted avg 0.84 0.84 0.84 150
4. 파이썬 코드
모든 평가지표는 sklearn.metrics 에 있다.
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import clssification_report
각 함수에 average=binary이 디폴트값이라서 다중 분류할 때는 average=None으로 지정해줘야한다.
참고
분류 모델의 평가 지표
정확도, 정밀도, 재현율, F1 score, Fbeta Score, ROC curve, AUC score
velog.io
https://white-joy.tistory.com/9
분류 모델 성능 평가 지표(Accuracy, Precision, Recall, F1 score 등)
분류 모델(classifier)을 평가할 때 주로 Confusion Matrix를 기반으로 Accuracy, Precision, Recall, F1 score를 측정한다. Confusion Matrix(혼동 행렬, 오차 행렬) 분류 모델(classifier)의 성능을 측정하는 데 자주 사용
white-joy.tistory.com
'교육 > KT 에이블스쿨' 카테고리의 다른 글
| [KT AIVLE] 회귀모델 성능평가지표 (0) | 2023.12.13 |
|---|---|
| [KT AIVLE] 1주차 - Python 프로그래밍 & 라이브러리 #4 (0) | 2023.08.20 |
| [KT AIVLE] 1주차 - Git② #3 (0) | 2023.08.19 |
| [KT AIVLE] 1주차 - Git① #2 (0) | 2023.08.16 |
| [KT AIVLE] 오프닝데이 후기 #1 (0) | 2023.08.08 |
분류 모델 성능 평가지표로는 Confusion Matrix(오분류표)를 바탕으로 Accuracy, Precision, Recall, F1-Score 이 있다.
1. Confusion Matrix
- TN : 음성으로 예측했는데 예측이 맞음! (음성으로 잘 예측한 것)
- TP : 양성으로 예측했는데 예측이 맞음! (양성으로 잘 예측한 것)
- FP : 양성으로 예측했는데 예측이 틀림! (예측 : 양성, 실제 : 음성)
- FN : 음성으로 예측했는데 예측이 틀림! (예측 : 음성, 실제 : 양성)
1.1 정확도 (Accuracy)
- 전체 중에서 양성, 음성 정확히 예측한(TN+TP) 비율
- 음성도 음성으로 예측한 경우도 옳은 예측임을 고려하는 평가지표
- 가장 직관적으로 모델 성능을 확인할 수 있는 평가지표
- 한계점으로 데이터 불균형시 제대로 분류했는지 알 수 없다.
1.2 정밀도 (Precision)
- 예측 관점에서 Positive라고 예측한 것 중에 실제 Positive인 비율
- ex) 비가 내릴 것으로 예측한 날 중에 실제 비가 내린 비율
- Positive 예측 성능을 정밀하게 측정하는 데 사용
1.3 재현율 (Recall)
- 실제 관점에서 실제 Positive 중에서 Positive로 예측한 비율
- ex) 실제 비가 내릴 날 중에서 비가 내릴 것으로 예측한 날의 비율
- 실제 Positive를 얼마나 잘 예측했는지 나타내는 데 사용
1.4 정밀도와 재현율의 관계
정밀도와 재현율은 분자는 같고 분모만 다르기 때문에 Trade-off 관계를 가지고 있다.
정밀도가 더 중요한 경우
- 실제 음성인 데이터를 양성으로 잘못 판단하게 되는 경우 (정상 -> 비정상)
- ex) 스팸메일이 아닌데 스팸메일로 판단하는 경우
재현율이 더 중요한 경우
- 실제 양성인 데이터를 음성으로 잘못 판단하게 되는 경우 (비정상 -> 정상)
- ex) 암인데 암이라고 진단 내리지 않은 경우
재현율과 정밀도 모두 TP를 높이는 목적을 가지고 있지만, 재현율은 FN을 낮추는데 초점을 맞추고 있고 정밀도는 FP를 낮추는데 초점을 맞추고 있다.
모델의 성능을 평가할 때 둘 다 높은 수치를 얻는 것이 가장 좋고, 한 쪽은 높지만 다른 한 쪽은 매우 낮은 경우는 좋지 않은 모델이라고 평가할 수 있다.
2. F1-score
- Recall과 Precision의 조화평균
- Recall과 Precision 한 쪽으로 치우치지 않고 모두 클 때 큰 값을 가진다.
3. classification_report
위 방법을 한 번에 보여주는 코드이다. 오른쪽 맨 마지막은 개수이다.
# 모듈 불러오기
from sklearn.metrics import classification_report
# 성능 평가
print(classification_report(y_test,y_pred)) precision recall f1-score support
0 0.83 0.90 0.86 84
1 0.86 0.76 0.81 66
accuracy 0.84 150
macro avg 0.84 0.83 0.84 150
weighted avg 0.84 0.84 0.84 150
4. 파이썬 코드
모든 평가지표는 sklearn.metrics 에 있다.
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import clssification_report
각 함수에 average=binary이 디폴트값이라서 다중 분류할 때는 average=None으로 지정해줘야한다.
참고
분류 모델의 평가 지표
정확도, 정밀도, 재현율, F1 score, Fbeta Score, ROC curve, AUC score
velog.io
https://white-joy.tistory.com/9
분류 모델 성능 평가 지표(Accuracy, Precision, Recall, F1 score 등)
분류 모델(classifier)을 평가할 때 주로 Confusion Matrix를 기반으로 Accuracy, Precision, Recall, F1 score를 측정한다. Confusion Matrix(혼동 행렬, 오차 행렬) 분류 모델(classifier)의 성능을 측정하는 데 자주 사용
white-joy.tistory.com
'교육 > KT 에이블스쿨' 카테고리의 다른 글
| [KT AIVLE] 회귀모델 성능평가지표 (0) | 2023.12.13 |
|---|---|
| [KT AIVLE] 1주차 - Python 프로그래밍 & 라이브러리 #4 (0) | 2023.08.20 |
| [KT AIVLE] 1주차 - Git② #3 (0) | 2023.08.19 |
| [KT AIVLE] 1주차 - Git① #2 (0) | 2023.08.16 |
| [KT AIVLE] 오프닝데이 후기 #1 (0) | 2023.08.08 |