
데이터 분석 스터디에서 배운 웹 크롤링, 정리안해두면 까먹을 거 같아서 정리해보았슴다~
1. 웹 크롤링이란?
인터넷에 있는 웹 페이지를 방문해서 페이지의 자료를 자동으로 수집하는 작업을 의미한다. 이 포스팅에서는 셀레니움을 이용해서 웹 크롤링을 할 것이다.
(대표적으로 파이썬 웹 크롤링 프레임워크/라이브러리는 BeautifulSoup와 Selenium이 있다)
2. Chrome Driver 설치하기
2.1 Chrome 버전 확인
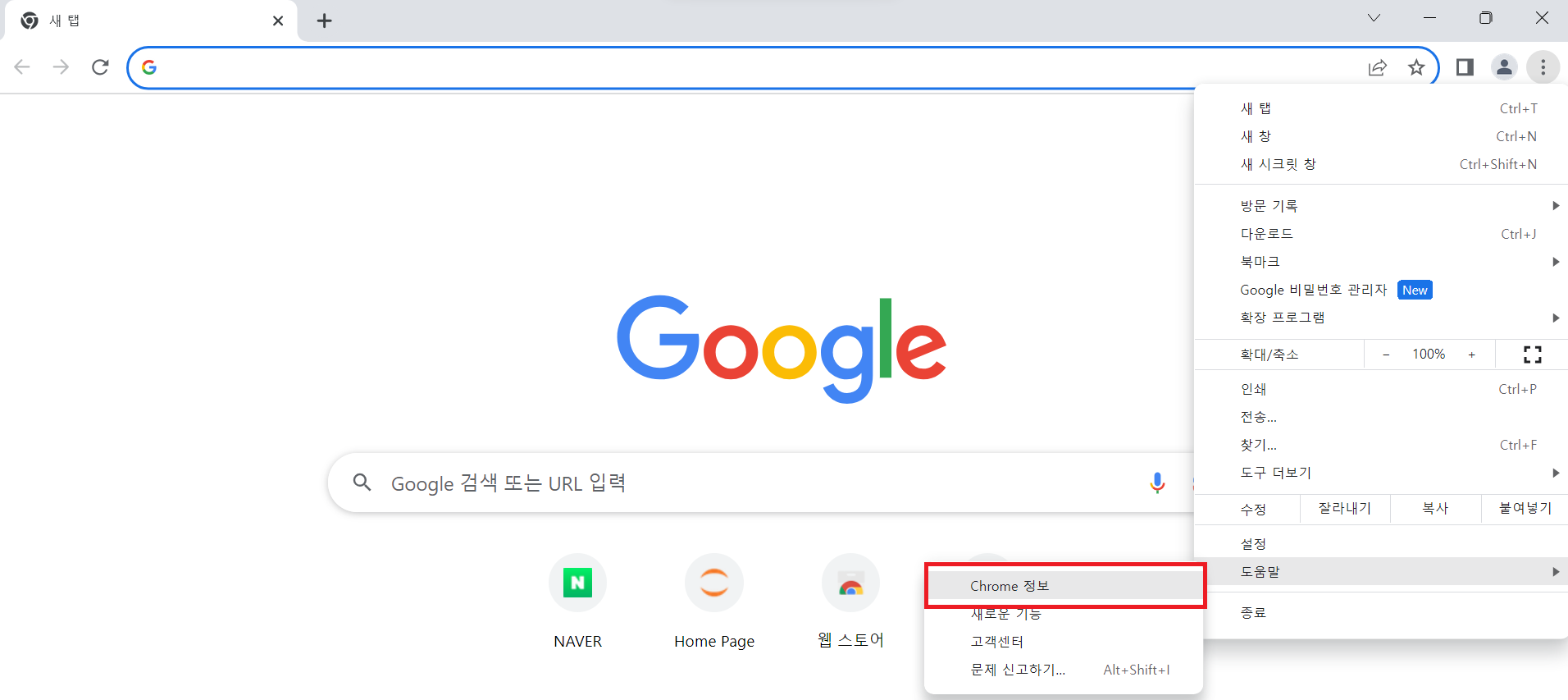
Chrome 정보를 누른 후에 나온 화면에서
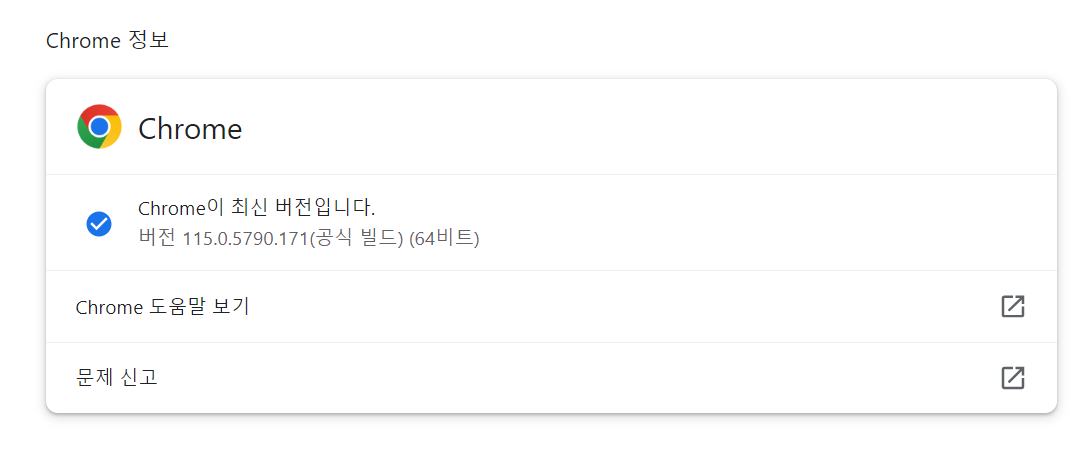
Chrome 버전을 확인할 수 있다.
2.2 Chrome Driver 다운로드
다운로드 링크를 누르고 2.1에서 확인한 Chrome버전과 맞은 드라이버를 설치한다.
그 후 자신이 크롤링하고자 하는 파이썬 폴더에 크롬 드라이버를 넣어주면 된다.
만약 파이썬 폴더에 크롬 드라이버가 들어있지 않다면, 웹 크롤링하는데 있어 작동을 하지 않는다...!
3. 데이터 크롤링 실전 예제
네이버 뉴스에 있는 언론사별로 랭킹뉴스 1~10위까지를 크롤링해보자.

3.1 Selenium 설치
!pip install selenium
3.2 Selenium 사용
필요한 라이브러리를 불러온 후에
# 라이브러리
# !pip install selenium
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By크롤링할 주소를 알려준다.
아래 코드는 '언론사별 랭킹뉴스' 홈페이지까지 접속하는 것을 자동화한 코드이다.
# 크롬 웹드라이버 실행 경로
path = 'chromedriver.exe'
# 크롤링할 주소
target_url = "https://news.naver.com/"
# 크롬 드라이버 사용
service = Service(executable_path=path) # selenium 최근 버전은 이렇게 해야함.
# 이런 것 때문에 기술문서를 보면서 코딩해야하고 영어도 잘해야함. (by. 스터디 팀장님)
options = webdriver.ChromeOptions()
driver = webdriver.Chrome()
# 드라이버에게 크롤링할 대상 알려주기
driver.get(target_url)
driver.implicitly_wait(2) # 2초 안에 웹페이지를 load하면 바로 넘어가거나, 2초를 기다림
# 랭킹뉴스 클릭
driver.find_element(By.XPATH,'/html/body/section/header/div[2]/div/div/div[1]/div/div/ul/li[8]/a').click()XPATH란? 마크업 언어에서 특정 요소를 찾기 위한 경로를 나타내는 언어
위 코드를 실행하면

자동으로 이런 화면이 나온다.
주소 밑에 'Chrome이 자동화된 테스트 소프트웨어에 의해 제어되고 있습니다.' 이는 크롤링을 하고 있다는 표시!
여기서 F12를 눌러서 HTML코드를 보면

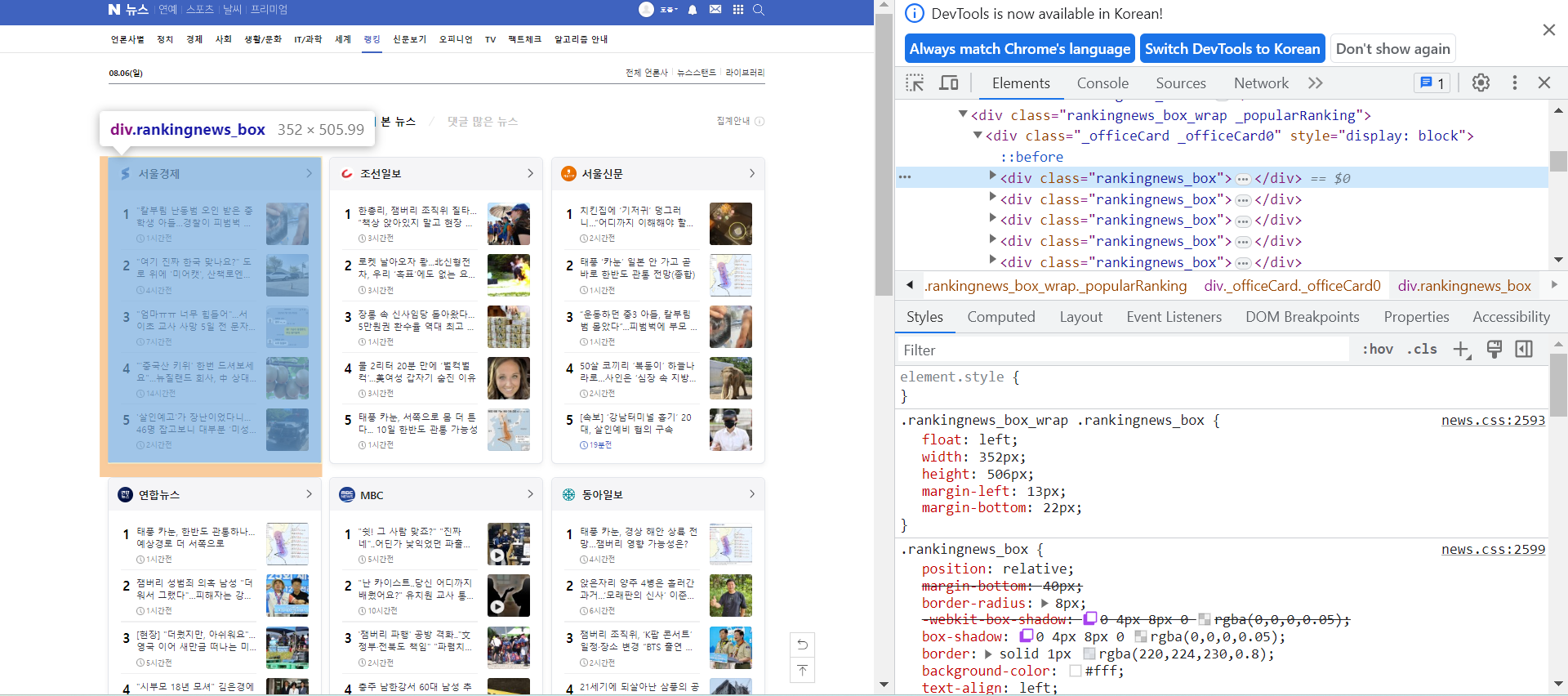
<div> 태그 안에 <div> 태그들이 언론사별로 묶여있는 것을 확인할 수 있다.
이를
journalism = driver.find_element(By.XPATH,'//*[@id="wrap"]/div[4]/div[2]') # 언론사별 랭킹뉴스 box
journalism_list = journalism.find_elements(By.CLASS_NAME,'rankingnews_box') # 각 언론사별 boxXPATH를 이용해서 들고와서 CLASS_NAME을 따로 추출하면
journalism_list 변수안에는

div태그가 리스트형식으로 들어간다.
여기서

a태그에 있는 href속성을 따로 추출한다.
url_news = []
for head in journalism_list:
tag_name = head.find_element(By.TAG_NAME,'a') # a태그 찾아서
href = tag_name.get_attribute('href') # 그 안에 href속성, 중앙일보, 서울경제 등 데이터 들어있음
print(href)
url_news.append(href)https://media.naver.com/press/005/ranking?type=popular
https://media.naver.com/press/025/ranking?type=popular
https://media.naver.com/press/003/ranking?type=popular
https://media.naver.com/press/009/ranking?type=popular
https://media.naver.com/press/001/ranking?type=popular
https://media.naver.com/press/020/ranking?type=popular
https://media.naver.com/press/028/ranking?type=popular
https://media.naver.com/press/011/ranking?type=popular
https://media.naver.com/press/016/ranking?type=popular
https://media.naver.com/press/437/ranking?type=popular
https://media.naver.com/press/023/ranking?type=popular
https://media.naver.com/press/057/ranking?type=populardiv태그 -> a태그 -> href속성 순으로!
url_news안에 링크를 하나씩 돌면서 언론사 이름을 추출하고,

XPATH와 CLASS_NAME등을 이용해서 위에 했던 방식으로 비슷하게 1~10위 뉴스를 가져온다.
(코드가 비슷해서 설명은 생략 ..)

for head in journalism_list:
tag_name = head.find_element(By.TAG_NAME,'a') # a태그 찾아서
# print(tag_name)
href = tag_name.get_attribute('href') # 그 안에 href속성, 중앙일보, 서울경제 등 데이터 들어있음
print(href)
url_news.append(href)
for url in url_news:
driver.get(url)
press_name = driver.find_element(By.XPATH,'/html/body/div[2]/div/section[1]/header/div[4]/div/div[2]/div[1]/div/h3')
print(press_name.text) # 언론사 이름
rank = driver.find_element(By.XPATH, '//*[@id="ct"]/div[2]/div[2]/ul') # 1~10 랭킹 xpath
rank_url = rank.find_elements(By.CLASS_NAME,'as_thumb') # 뉴스 타이틀
url_top10=[] # 1~10위
for rank in rank_url:
tag_name = rank.find_element(By.TAG_NAME,'a') # a태그 찾아서
href = tag_name.get_attribute('href') # 그 안에 href속성
url_top10.append(href)
for i in range(0,len(url_top10)): # 각 언론사별 1~10위 뉴스
driver.get(url_top10[i])
news_title = driver.find_element(By.XPATH,'//*[@id="title_area"]/span')
print('{}등, {}'.format(i+1,news_title.text))전체 코드를 실행하면 결과는

이렇게 "언론사별 많이본 1~10위 뉴스"를 가져올 수 있다!
간단한 실습을 통해 셀레니움을 다루어보았다. 동적 페이지에서 사용되는 라이브러리이니 더 복잡한 실습을 통해 반드시 !! 숙지해놓자~~! 또한 다음에는 출력이 아닌 csv파일로 저장해보는걸로 해보겠습니다!
'Programming > Web Crowling' 카테고리의 다른 글
| [Python] Selenium을 이용한 캡처 및 스크린샷 저장하기 (0) | 2023.08.07 |
|---|