
해당 게시물은 LG Aimers 3기 활동 중 학습한 내용을 간단하게 정리하기 위해 작성하였습니다.
Learning from data
Q. 다음 그림이 어떤 동물인가??

A. 사자!
Q. 이 동물이 어떻게 사자인지 알게 되었나?
A. what....?
경험적으로 알게 되었다.. 선생님이나 부모님 또는 책에서 이 그림이 사자라고 계속해서 교육을 받아서 네발을 가지고 이빨이 날카롭고 목 주위에 갈기를 가진 것과 같은 패턴을 가진 동물을 사자임을 이해하게 된다..!
Machine Learning 도 이와 비슷하게 Data로부터 내재된 패턴을 학습하는 과정이라고 할 수 있다.
Machine learning case
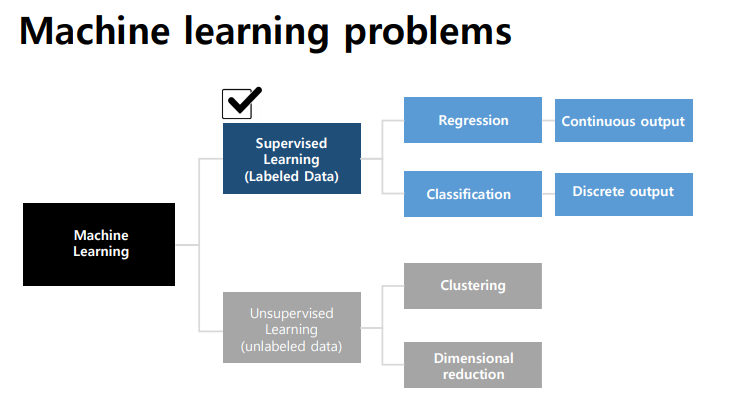
Machine learning case
- 메일이 스팸인지, 아닌지
- 입력 이미지를 기반으로 한 이미지를 분류하는 문제
- 집 값 예측
등등 Supervised Learing(지도학습)의 일종이다.
Supervised Learing
- Supervised Learning에서 사용하는 data sample은 (x,y)로 구성되어 있다. x-> y로 가는 함수를 학습해서 새로운 입력값이 들어왔을 때 category label를 맞추게 하는 것이다.
Learning pipeline
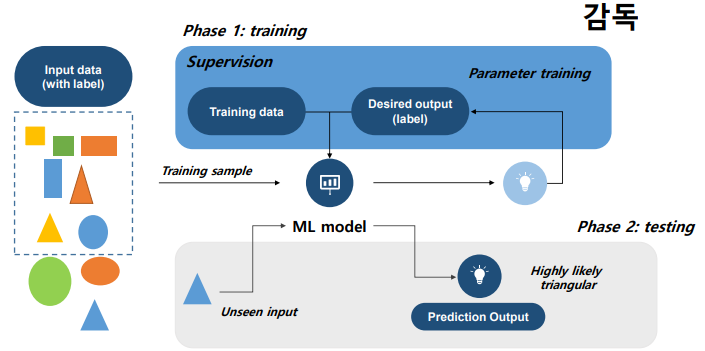
- Phase1 - training : 머신러닝 모델이 model output과 정답과의 차이인 error를 통해서 error를 줄여가면서 학습을 한다. 학습 sample의 label이 주어짐으로 가능한 일이며 이것이 바로 supervised Learning의 기본아이디어이다.
- Phase2 - test : model이 실제 환경에 적용되는 것을 의미, training 단계에서 보지 못했던 새로운 입력 값을 이용한다. 모델 정확도가 곧 성능이 될 것이다.
Learning model
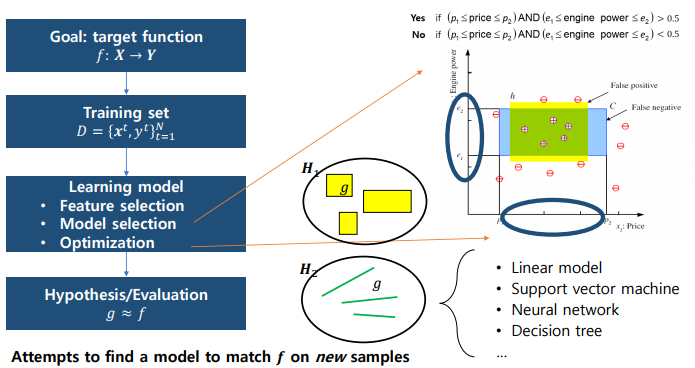
- target function f를 모사
- real world에서 나타나는 sample들의 realization으로서의 data set을 활용
- 모델을 학습하는 과정에서는 feature selection, Model selection, Optimization과정을 거친다.
- Model selection은 풀고자 하는 문제에 가장 적합한 model를 선택하는 과정이다.
ex) target function f가 파란색 박스와 같은 분포로 있을 것이라고 생각된다면 그와 같은 decision boundary를 가지는 model을 선택하는 것이 바람직할 것이다.
- Optimization은 모델 parameter를 최적화하여 model이 가장 우수한 성능을 제공하도록 하는 것이다.
Model generalization
"Machine Learing은 그 자체로 Data의 결핍으로 인한 불확실성을 포함하고 있다." 학습 과정에서 우리가 모든 data sample들을 관찰할 수가 없기 때문이다. 그래서 머신러닝 학습 중 가장 중요한 것 중 하나는 일반화이다. 모델이 처음보는 데이터에 있어서 바로 우수한 성능을 제공할 수 있어야 한다.
model의 일반화된 성능을 측정하기 위한 measurement로써 E를 정의해보자.
Error, E
- Error는 각 샘플 별로 pointwise로 계산한다. h(x)는 모델의 출력이고, y는 정답이다.
- squared error : model 출력과 정답과의 차이를 제곱하여 계산한다.
- binary error : 내부의 logic을 판별하여 맞으면 0, 틀리면 1인 함수이다.
- 최종적으로는 data sample에서 발생하는 모든 sample들의 pointwise error를 합쳐서 overall error를 계산한다. 이를 loss function 혹은 cost function이라고도 부른다.
- E(train)은 model을 주어진 data set에 맞추어 학습하는데 사용하는 error이다. 그렇기 때문에 이 error를 E(general)을 approximation하는데 적합하지 않다.
- E(test)은 이 모델이 real world에서 적용될 때 나타나는 E(general) 표현한 것이라고 생각할 수 있다.
- 우리의 목적은 E(test)가 0으로 근사하도록 하여 E(general)도 0으로 근사할 수 있다는 기대를 갖게 하는 것이다.
- 수행방법 :
- ① E(test)와 E(train)이 가깝게 되도록 만드는 것이다.
- ② E(train)이 0으로 되게 하는 것이다.
- Obj①. 우리가 학습한 모델이 일반적인 성능을 제공하도록 하는 기능을 갖도록 하는 것이다. 즉, 분산이 작도록 해야한다. 실패 시 , overfitting이 나타난다.
- Obj②. 모델의 정확도가 올라가는 것이다. 즉, 편차가 낮아지도록 해야한다. 실패 시, underfitting이 나타난다.
Underfitting
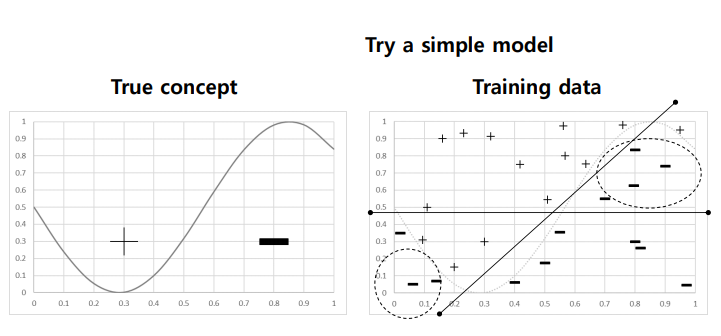
왼쪽 그림과 같이 decision boundary이 이상적으로 존재한다고 할 때, 모델을 학습하면(위 사진은 간단한 선형 모델) 효과적으로 approximation할 수 없기 때문이다. 이 문제를 high bias라고도 한다.
Overfitting
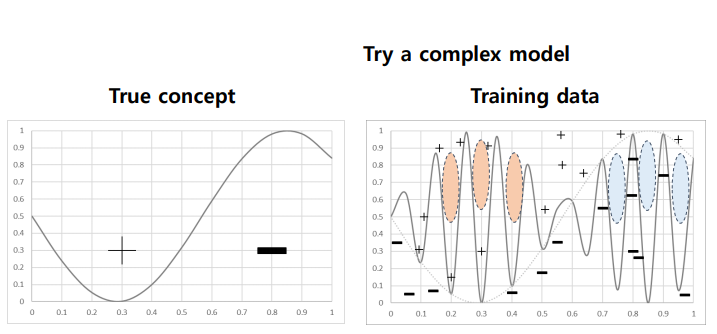
high bias 문제를 해결하기 위해서 지나치게 복잡한 모델을 도입하면, training data는 정확하게 분류할 수 있지만, 색칠되어 있는 부분에서 오분류가 발생한다.이 문제를 high variance라고 한다.
Bias-variance trand-off

모델의 복잡도에 의해 두 가지 목적은 trade-off 관계를 가진다. 모델이 복잡해지면 overfitting이 발생하기 쉬우며 bias가 줄어들지만 variance가 증가하게 된다. 모델이 새로운 샘플에 일반적인 성능을 기대하기 어렵다.
반대로 모델이 단순하다면 underfitting이 발생해서 bias가 높아지며 우수한 성능을 제공하기 어렵다.
이 두 개 factor를 trand-off해서 E(general)을 최소화하는 것이 학습 과정에서 중요하다.
Avoid overfitting
요즘은 이미지나 비디오 등과 같은 고차원의 data를 다루기 때문에 복잡도가 계속 증가하고 있다. 그에 반해 데이터 샘플은 쉽게 늘리지 못해 overfitting문제가 많아지고 있다. 이 문제를"Curse of dimension"이라고 한다.
대비 방법
- Regulaization : 뒤에서 설명
- Ensemble : 뒤에서 설명
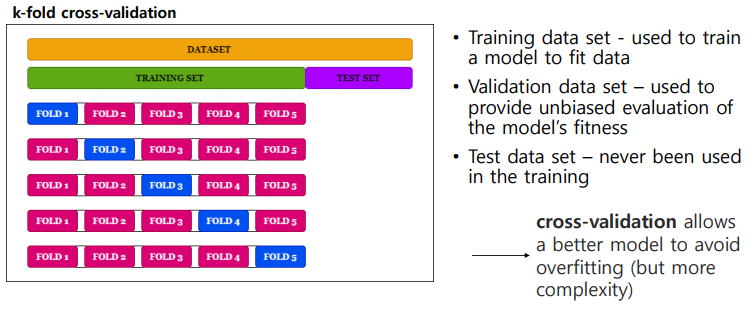
- k-fold cross-validation : training set를 k개의 그룹으로 나누어 k-1을 training으로 사용하고 나머지를 validation으로 사용하는 방법이다. 이러한 과정을 수행해서 데이터 샘플들을 자연스럽게 augmentation해서 학습을 하는데 활용하면 모델을 일반화시키는데 도움을 줄 수 있다.
'교육 > LG Aimers' 카테고리의 다른 글
| [LG Aimers] Module 1. AI Ethics (0) | 2023.07.04 |
|---|
해당 게시물은 LG Aimers 3기 활동 중 학습한 내용을 간단하게 정리하기 위해 작성하였습니다.
Learning from data
Q. 다음 그림이 어떤 동물인가??
A. 사자!
Q. 이 동물이 어떻게 사자인지 알게 되었나?
A. what....?
경험적으로 알게 되었다.. 선생님이나 부모님 또는 책에서 이 그림이 사자라고 계속해서 교육을 받아서 네발을 가지고 이빨이 날카롭고 목 주위에 갈기를 가진 것과 같은 패턴을 가진 동물을 사자임을 이해하게 된다..!
Machine Learning 도 이와 비슷하게 Data로부터 내재된 패턴을 학습하는 과정이라고 할 수 있다.
Machine learning case
Machine learning case
- 메일이 스팸인지, 아닌지
- 입력 이미지를 기반으로 한 이미지를 분류하는 문제
- 집 값 예측
등등 Supervised Learing(지도학습)의 일종이다.
Supervised Learing
- Supervised Learning에서 사용하는 data sample은 (x,y)로 구성되어 있다. x-> y로 가는 함수를 학습해서 새로운 입력값이 들어왔을 때 category label를 맞추게 하는 것이다.
Learning pipeline
- Phase1 - training : 머신러닝 모델이 model output과 정답과의 차이인 error를 통해서 error를 줄여가면서 학습을 한다. 학습 sample의 label이 주어짐으로 가능한 일이며 이것이 바로 supervised Learning의 기본아이디어이다.
- Phase2 - test : model이 실제 환경에 적용되는 것을 의미, training 단계에서 보지 못했던 새로운 입력 값을 이용한다. 모델 정확도가 곧 성능이 될 것이다.
Learning model
- target function f를 모사
- real world에서 나타나는 sample들의 realization으로서의 data set을 활용
- 모델을 학습하는 과정에서는 feature selection, Model selection, Optimization과정을 거친다.
- Model selection은 풀고자 하는 문제에 가장 적합한 model를 선택하는 과정이다.
ex) target function f가 파란색 박스와 같은 분포로 있을 것이라고 생각된다면 그와 같은 decision boundary를 가지는 model을 선택하는 것이 바람직할 것이다.
- Optimization은 모델 parameter를 최적화하여 model이 가장 우수한 성능을 제공하도록 하는 것이다.
Model generalization
"Machine Learing은 그 자체로 Data의 결핍으로 인한 불확실성을 포함하고 있다." 학습 과정에서 우리가 모든 data sample들을 관찰할 수가 없기 때문이다. 그래서 머신러닝 학습 중 가장 중요한 것 중 하나는 일반화이다. 모델이 처음보는 데이터에 있어서 바로 우수한 성능을 제공할 수 있어야 한다.
model의 일반화된 성능을 측정하기 위한 measurement로써 E를 정의해보자.
Error, E
- Error는 각 샘플 별로 pointwise로 계산한다. h(x)는 모델의 출력이고, y는 정답이다.
- squared error : model 출력과 정답과의 차이를 제곱하여 계산한다.
- binary error : 내부의 logic을 판별하여 맞으면 0, 틀리면 1인 함수이다.
- 최종적으로는 data sample에서 발생하는 모든 sample들의 pointwise error를 합쳐서 overall error를 계산한다. 이를 loss function 혹은 cost function이라고도 부른다.
- E(train)은 model을 주어진 data set에 맞추어 학습하는데 사용하는 error이다. 그렇기 때문에 이 error를 E(general)을 approximation하는데 적합하지 않다.
- E(test)은 이 모델이 real world에서 적용될 때 나타나는 E(general) 표현한 것이라고 생각할 수 있다.
- 우리의 목적은 E(test)가 0으로 근사하도록 하여 E(general)도 0으로 근사할 수 있다는 기대를 갖게 하는 것이다.
- 수행방법 :
- ① E(test)와 E(train)이 가깝게 되도록 만드는 것이다.
- ② E(train)이 0으로 되게 하는 것이다.
- Obj①. 우리가 학습한 모델이 일반적인 성능을 제공하도록 하는 기능을 갖도록 하는 것이다. 즉, 분산이 작도록 해야한다. 실패 시 , overfitting이 나타난다.
- Obj②. 모델의 정확도가 올라가는 것이다. 즉, 편차가 낮아지도록 해야한다. 실패 시, underfitting이 나타난다.
Underfitting
왼쪽 그림과 같이 decision boundary이 이상적으로 존재한다고 할 때, 모델을 학습하면(위 사진은 간단한 선형 모델) 효과적으로 approximation할 수 없기 때문이다. 이 문제를 high bias라고도 한다.
Overfitting
high bias 문제를 해결하기 위해서 지나치게 복잡한 모델을 도입하면, training data는 정확하게 분류할 수 있지만, 색칠되어 있는 부분에서 오분류가 발생한다.이 문제를 high variance라고 한다.
Bias-variance trand-off
모델의 복잡도에 의해 두 가지 목적은 trade-off 관계를 가진다. 모델이 복잡해지면 overfitting이 발생하기 쉬우며 bias가 줄어들지만 variance가 증가하게 된다. 모델이 새로운 샘플에 일반적인 성능을 기대하기 어렵다.
반대로 모델이 단순하다면 underfitting이 발생해서 bias가 높아지며 우수한 성능을 제공하기 어렵다.
이 두 개 factor를 trand-off해서 E(general)을 최소화하는 것이 학습 과정에서 중요하다.
Avoid overfitting
요즘은 이미지나 비디오 등과 같은 고차원의 data를 다루기 때문에 복잡도가 계속 증가하고 있다. 그에 반해 데이터 샘플은 쉽게 늘리지 못해 overfitting문제가 많아지고 있다. 이 문제를"Curse of dimension"이라고 한다.
대비 방법
- Regulaization : 뒤에서 설명
- Ensemble : 뒤에서 설명
- k-fold cross-validation : training set를 k개의 그룹으로 나누어 k-1을 training으로 사용하고 나머지를 validation으로 사용하는 방법이다. 이러한 과정을 수행해서 데이터 샘플들을 자연스럽게 augmentation해서 학습을 하는데 활용하면 모델을 일반화시키는데 도움을 줄 수 있다.
'교육 > LG Aimers' 카테고리의 다른 글
| [LG Aimers] Module 1. AI Ethics (0) | 2023.07.04 |
|---|